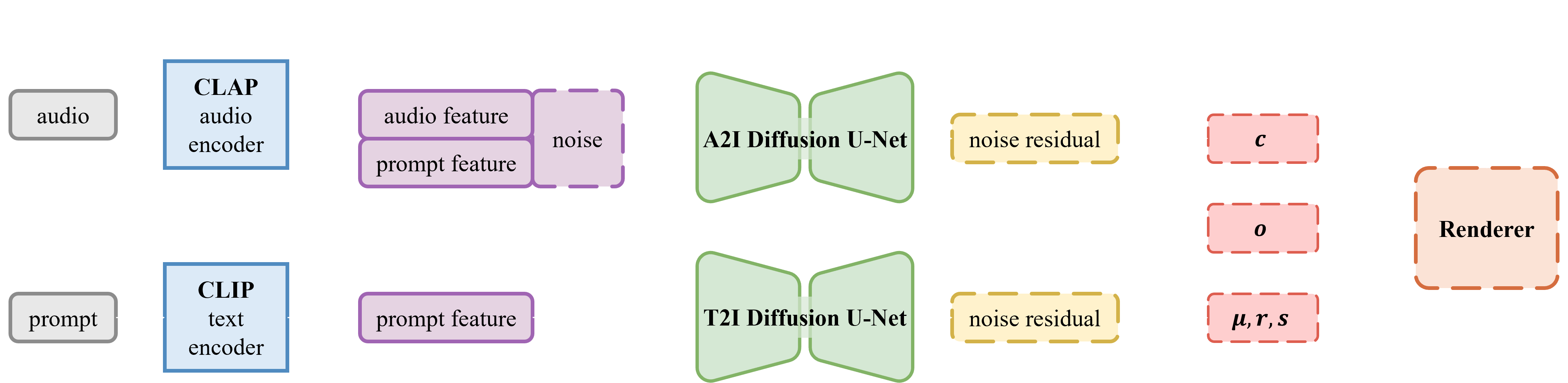
Method Overview
SFX-to-3D Generation Results
Audio: 🔊 (Fire Cracking)
Audio: 🔊 (Forest)
Audio: 🔊 (Forest)
Audio: 🔊 (Underwater Bubbling)
A23D Result:
Audio: 🔊 (Snow)
A23D Result:
Our system is capable of audio-driven 3D mesh and texture generation using pretrained 2D diffusion models from only single audio file.
Ablation: Modality-Cross 3D Generation
Audio: 🔊 (Null)
Text: 💬 "A chair with fire crackling effect"
Text-to-2D:
Audio: 🔊 (Null)
Text: 💬 "A chair with fire crackling effect"
Text-to-3D:
Audio: 🔊 (Fire Cracking)
Text: 💬 "A Chair"
(Naïve) Audio-Driven Text-to-3D:
Audio: 🔊 (Fire Crackling)
Text: 💬 "A Chair"
Ours: